Este tutorial é uma contribuição da comunidade e não é suportado pela equipe Nullcore. Serve apenas como uma demonstração sobre como personalizar o Nullcore para o seu caso de uso específico. Quer contribuir? Confira o tutorial contribuinte.
Este guia é verificado com a configuração aberta da webui atravésInstalação manual
Configuração local LLM com ipex-llm na GPU Intel
Ipex-llmé uma biblioteca Pytorch para executar o LLM na Intel CPU e GPU (por exemplo, PC local com IGPU, GPU discreto, como ARC A-Series, Flex e Max) com latência muito baixa.
Este tutorial demonstra como configurar o webui aberto comO back-end da IPEX-LLM acelerou o backend hospedado na Intel GPU. Seguindo este guia, você poderá configurar o Nullcore, mesmo em um PC de baixo custo (ou seja, apenas com a GPU integrada) com uma experiência suave.
Start Ollama serve na Intel GPU
Consulteeste guiaA partir da documentação oficial do iPex-llm sobre como instalar e executar o servir de Ollama acelerado pelo ipex-llm na Intel GPU.
Se você deseja alcançar o serviço ollama de outra máquina, certifique -se de definir ou exportar a variável de ambienteOLLAMA_HOST=0.0.0.0Antes de executar o comandoollama serve
Configure o Nullcore
Acesse as configurações de Ollama atravésConfigurações -> conexõesno menu. Por padrão, oUrl base ollamaé predefinido parahttps: // localhost: 11434, conforme ilustrado no instantâneo abaixo. Para verificar o status da conexão de serviço ollama, clique noBotão de atualizaçãolocalizado próximo à caixa de texto. Se o webui não puder estabelecer uma conexão com o servidor ollama, você verá uma mensagem de erro informando,WebUI could not connect to Ollama
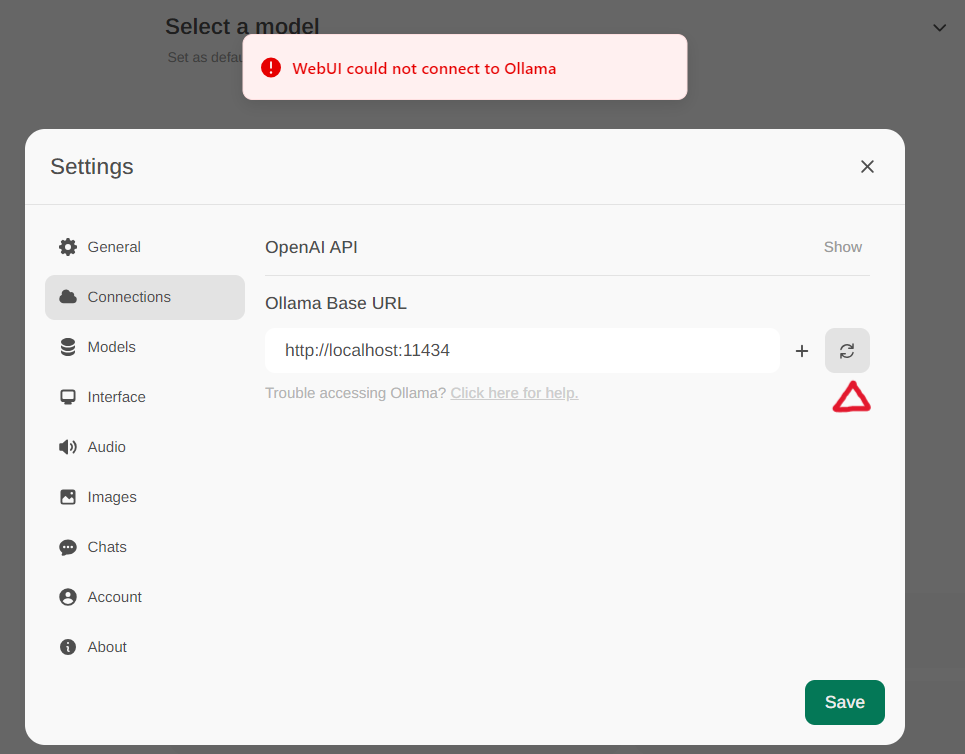
Se a conexão for bem -sucedida, você verá uma mensagem informandoService Connection Verified, como ilustrado abaixo.
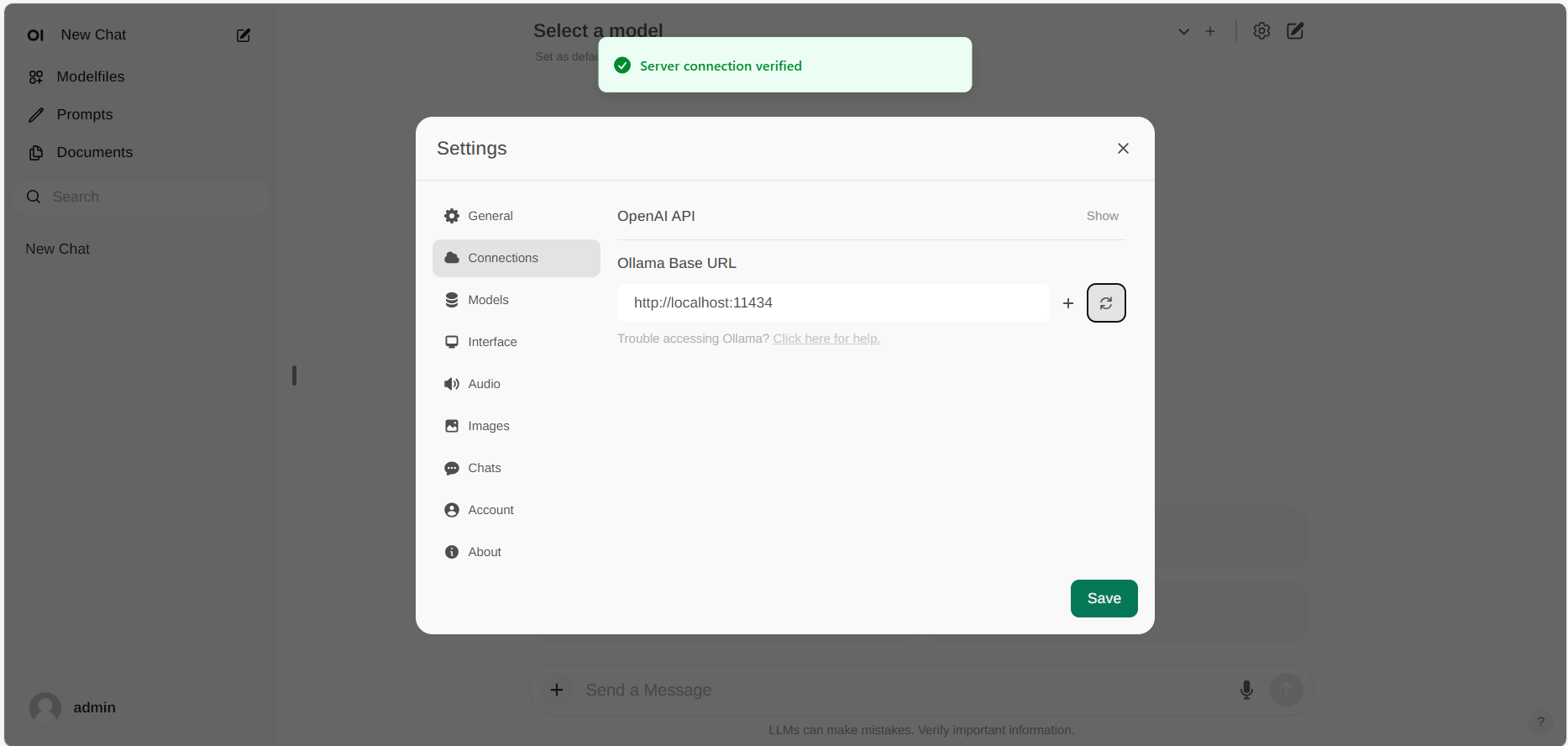
Se você deseja usar um servidor ollama hospedado em um URL diferente, basta atualizar oUrl base ollamapara o novo URL e pressione oAtualizarBotão para confirmar novamente a conexão com Ollama.